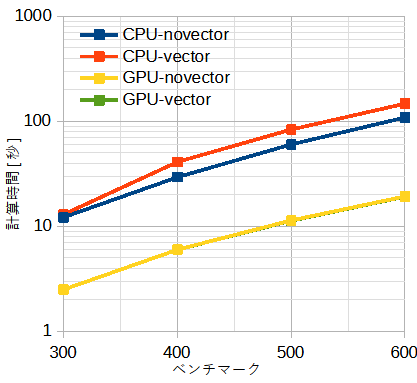
図3-6-1 計算時間のまとめ(CPU:8スレッド、単精度 共通)
表3-6-1に各手法の計算時間を示します。
ハードウェアの詳細は3.1の通りです。
CPUではOpenMPまたはMPIによる並列化はほぼ同等で5~6倍速くなります。
GPUでは約30倍速くなります。
| ハードウェア | 並列化手法 | ベンチマーク400 | ベンチマーク500 | ベンチマーク600 | 出所 |
|---|---|---|---|---|---|
| CPU | (参考)並列化なし | 174.3秒 (1.0) | 348.1秒 (1.0) | 597.0秒 (1.0) | 新規 |
| CPU | OpenMP 8スレッド | 29.4秒 (5.9) | 60.3秒 (5.8) | 108.9秒 (5.5) | 表3-2-2 |
| CPU | MPI 8プロセス | 31.5秒 (5.5) | 63.7秒 (5.5) | 109.8秒 (5.4) | 表3-3-2 |
| GPU | CUDA | 6.0秒 (29.1) | 11.4秒 (30.5) | 19.3秒 (30.9) | 表3-4-1 |
図3-6-1にCPU/GPUのnovector/vectorモードの計算時間を示します。
(出所: 表3-2-2、表3-4-1)
CPU,GPUともに使用メモリーが少なく速いnovectorモードを推奨します。